











Patent AI Benchmarking Explained: Why General LLMs Fall Short
Currently Playing Post:Patent AI Benchmarking Explained: Why General LLMs Fall Short
Patents serve to protect innovation, yet navigating them remains one of the most complex, high-stakes workflows in modern industry.
While general LLMs can handle some superficial patent search tasks, they are not purpose-built for IP.
Can general LLMs truly understand the precision of a claim set? Can it support high-risk decisions like novelty search or early-stage drafting? Where does it shine and where does it still fail?
PatentBench was built to answer these questions.
PatentBench is the first benchmark designed to test how AI performs on real patent tasks, beginning with one of the most rigorous: novelty search. Using expertly curated disclosures and gold-standard references, it brings clarity, structure, and measurable standards to a domain that has lacked all three for far too long.
Why Patsnap Built PatentBench
PatentBench is the first comprehensive benchmark built specifically for patent-focused AI. It evaluates models on two essential dimensions:
- Ten Core Patent Capabilities — the foundational skills a patent-aware LLM must have (e.g., interpretation, translation, drafting, reasoning)
- Patent Task Applications — real-world workflows such as novelty/prior art search, FTO (freedom-to-operate) analysis, translation, specification drafting, image-based infringement detection.
With PatentBench, patent-AI moves from loose “toy model” experiments to measurable, repeatable performance where models can be tracked, compared, improved.
Patent professionals can finally select the best tool with confidence, significantly reducing evaluation time and guess work. The industry gains a transparent standard, raising the bar and encouraging stronger, more capable AI patent models.
With PatentBench, Patsnap is redefining what AI can deliver for IP. The era of generic large language models pretending to solve patent problems is over.
It’s time to choose AI built with patent-expertise baked in.
A Glimpse into our PatentBench Methodology
The Patsnap PatentBench is a benchmark specifically for novelty search tasks in real-world patent scenarios.
It evaluates the performance of three AI tools: Patsnap’s Novelty Search AI Agent, ChatGPT-o3 (with web search), and DeepSeek-R1 (with web search).
Key Results and Findings
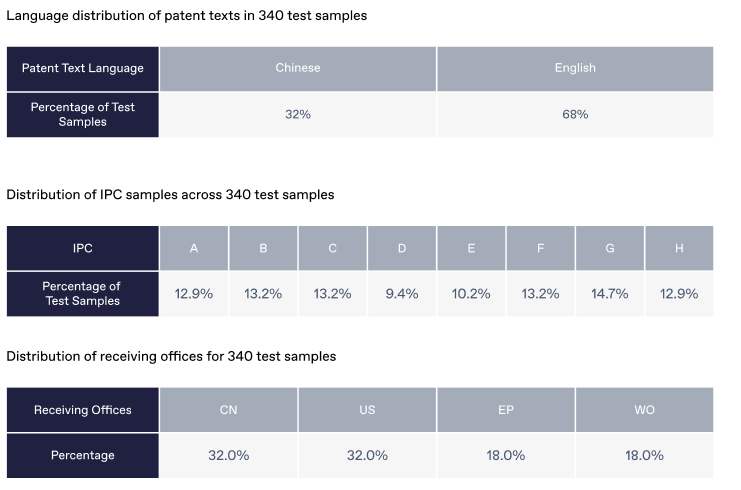
The evaluation dataset is evenly distributed across IPC classifications, covering both mainstream technologies and niche domains. In terms of language, 68% of the data is in English and 32% of the data is in Chinese, ensuring the model performs well across multilingual patent content. For receiving-office distribution, applications from United States (US) and China (CN) each make up about 32%, while those from the European Patent Office (EP) and WIPO (WO) each account for roughly 18%. This balanced mix reflects the different examination styles across major patent jurisdictions and ensures more realistic, globally representative evaluation.
X Hit Rate:Proportion of samples where a correct answer appears among the top 1, 3, or 5 results.
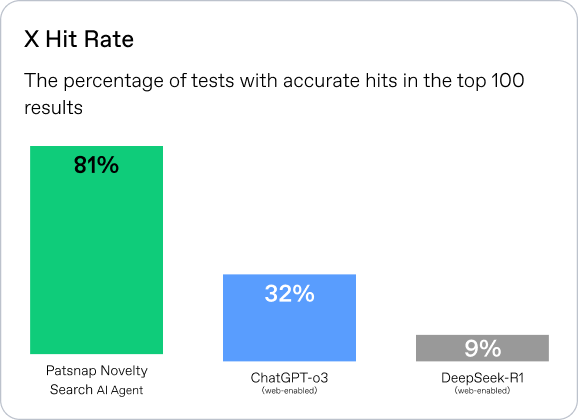
In our benchmark testing, the Novelty Search AI Agent achieved an 81% X-document hit rate within the Top 100 returned results.
X Recall Rate:Measures how well an AI tool retrieves X documents, which is crucial during R&D planning and pre-patent filing. A higher recall helps teams refine technical solutions and draft stronger claims. It’s calculated as the proportion of X documents retrieved in the top 100 results, relative to the total X documents across all test samples.
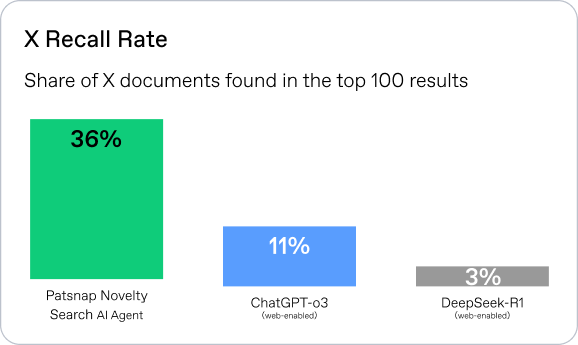
The X-document recall rate hit 36% compared to the ChatGPT-o3 and DeepSeek-R1.
Ready to see the difference? Book a demo with Patsnap today and discover how Patsnap Novelty Search AI Agent can transform your entire IP workflow.